Anatomy of an AI application
A high level overview of an application that uses LLMs

I have been hard at work building a non trivial AI application. Looking back at the road so far, I thought it good to write up some of my experiences and the mental model I have developed.
What type of AI application are we talking about?
There are a ton of different applications for LLMs and generative AI inside software. Some of what I am going to describe will not generalise to all uses of LLMs.
The specific application I am talking about is one where the user interacts with the application through a chat interface as an assistant or partner in thought.
What I have been working on allows someone in a B2B sales team to do some of the following:
Ask for up to date information about a deal they are working on.
Request a review of the deal and get insights of how well this deal is going.
Analyse the 10Q filings and quarterly earnings call transcripts of a company they are interested in and identify topics or information they are interested in.
Bring back data from web searches about target accounts into the conversation and combine it with internal data from CRM and other sources to ask questions against.
Ask questions about internal documentation to help them better prepare for upcoming meetings. For example, have the assistant pull out relevant information on how best to position the company’s product against that of a competitor who they know are also targeting this account.
The application is built in such a way that new skills can be added over time.
This type of application is very similar to the interfaces of chat apps such as ChatGPT and Google’s Gemini. However we can also embed it into line of business applications, making it more integrated into the daily lives of our users.
A mental model
LLMs might look like magic at times yet other times like utter nonsense spouting wastes of time. In order to make them useful it helps to have a good mental model of how these applications function.
You see the LLM part of the application is just the piece that handles the text translation from and to the user. Underneath the surface a ton of things are happening to make the LLM look intelligent.
My mental model for these types of applications is that each conversation is an A4 page being filled with user input, data returned from tools, and the LLM’s response based on the conversation on that page so far. Let me try and illustrate this graphically.

You have probably heard the word “context” mentioned a lot in Gen AI conversations. This entire A4 page that we build up serves as the context that we feed to our LLM for it to then generate an answer.
Now depending on how sophisticated you get you can send pieces of the A4 page to different LLMs tasked with specific functions. In these cases the pieces of the A4 page you send to the LLMs will be the context. As you will learn, context (or "cheating" as Steve Yegge puts it) is absolutely king.
When I started out I had the idea that I might need to train my own LLMs to perform certain tasks. You might have also heard others talk about fine tuning models to perform better at certain tasks. I will do my best to give some useful thoughts on this. However for a lot, and I mean the vast majority of what you might be doing, context is going to be your secret sauce.
Context is everything
The majority of AI applications, at least the kind I am describing here, will do some form of RAG. When people think about RAG they normally think about Vector databases. This is however only one form of RAG.
RAG (retrievement augmented generation) is just one part of building up the context that an LLM is operating within. The context of an LLM comprises everything that is fed into the LLM that it operates on to give a response. This includes:
The prompt
Chat history (input from the user and response from LLM)
Data from function/tool calls
Data fetched from Vector stores
Data fetched from any source system
The better the information in the context the better the response from the LLM.
Not all parts of the context are visible to the end user. You might hide some of it in the background and only inject it into the prompt that you send to the LLM. This normally gives rise to that magical feeling of “The LLM knows things!”. The application looks magical to the user because they cannot see the big chunk of information the LLM is using to answer their questions. Yet every follow up question gets answered accurately.
With the increase in input token size for most models it is becoming much easier to build out large amounts of context. Some of these models now have a 1 million token input size which is a vast amount of text. Just keep in mind that throwing everything at the context is not always the best strategy and can lead to performance issues in both duration of LLM calls and the output it generates.
You can get sophisticated with your context strategy where you cherry pick the pieces of chat history and information you pass to the LLM on each conversation turn. This can lead to very good results.
Functions/Tools can be more than meets the eye
Function calling with LLMs can be so much more than what you see in the normal documentation. The documentation typically highlights that you provide the LLM with a list of function definitions and the LLM comes back to you with which function to call and what arguments to pass to the function’s parameters.
This hides the fact that the functions can be the entry point to a much more complex process. For example you could create entire Python packages in which you use additional LLM calls to perform actions all hidden behind an entry point function.
You also do not need to have the LLM choose the arguments for the parameters. You could simply let it choose which function to call and pass through whatever you would like to the function. This can be useful by not having to over engineer your main LLM’s prompt to deal with things like entity extraction for specific function parameters.
An example of this is the Deal Review package we use in our application. The main LLM only decides that the user is looking for a deal review, then we pass the user input with the rest of the desired context to the entry point function of the Deal Review package. The package uses a dedicated LLM call to do entity extraction, looking for the name of a deal or a particular ID in the user input. It then makes the necessary calls out to databases to get the deal information and feeds that into another LLM call that is specifically designed to perform a deal review. Once all of this has completed the resulting text is passed back to the user. This process neatly contains the deal review functionality and allows us to separate out the prompts used. It also allows us to test individual pieces of the application separately making life much easier.
As you can see a function call does not need to be just a simple function call.
Training your own LLM or Fine Tuning a model
Inevitably there will be discussions about training your own LLM or fine tuning a model.
The reality is that training your own LLM is not a trivial undertaking and is prohibitively expensive for most people and companies. We are talking millions of dollars, not to mention the massive amounts of data you need to collect in order to have any chance at producing something good. Training of foundation model LLMs is currently only feasible for very large organisations.
A much more reasonable option is to take an LLM (typically a foundation model) and fine tune it for a specific use case that you might have. This requires you to have a couple of hundred or thousand data points (depending on what you are trying to do), and does not come at the same cost as training an LLM from scratch. The fine tuned model can then be used for that nice use case where a foundation model with good prompt and context is just not giving you what you are after.
Most of the time you will end up with a normal LLM foundation model and the correct context giving you good results. If that fails you will move to a fine tuned model.
User experience
As with all applications the user only has the frontend interaction by which to judge the application.
For AI applications additional thought needs to be put into the user experience. We have all become accustomed to the ChatGPT style interfaces where you are having conversation with what looks like a single agent. It serves as your single point of contact through which you access all the other services, agents and tools. This feels like sitting in a meeting room with a single expert who relays messages to others behind the scenes and then answers you..
We started out in our team with such an interface before one of our team members highlighted how unnatural this is in the real world. We then pivoted to a user interface where the user can directly access the different agents and tools we provide if they choose to. This is the equivalent of being able to address everyone in the meeting room and having a discussion about the information they provide.
As an example the user could ask the Deal Review agent for a review of a specific deal. This agent then pushes a detailed set of deal information and its summary into the chat context. The conversation can then continue and asking other agents questions would result in them having access to this context as well.
All of the above functionality is thanks to some very nice UX design in the front end. We use “@” to allow a user to address an agent. If the agent requires more input from the user, such as to make a choice between a set of values, the UI keeps focus on that agent in the front end until it has all the user input it needs. This makes it an easy and familiar experience since most social media and messaging applications work this way. We found that once users were shown this functionality it was extremely natural to them.
We have also embedded our application within some of the applications used by our users. This has made it easy for them to click on a “AI Chat” icon next to an account which would launch the chat interface with the account’s information preloaded into the context with an account review provided straight away. They can then continue the conversation from that point.
Most of what we have done on the UX side is to observe how our users work normally, then sprinkle our AI application into their normal workflows. This has made ordinary tools seem magical.
Technical components at a high level
The final thing I want to do is give a high level view of the technical components that make up the solution. We started out with a more complicated set of components and over time simplified it. This gave us the ability to focus more on the application’s functionality than keeping an eye on the infrastructure.
Below is a diagram of the main components we currently have.
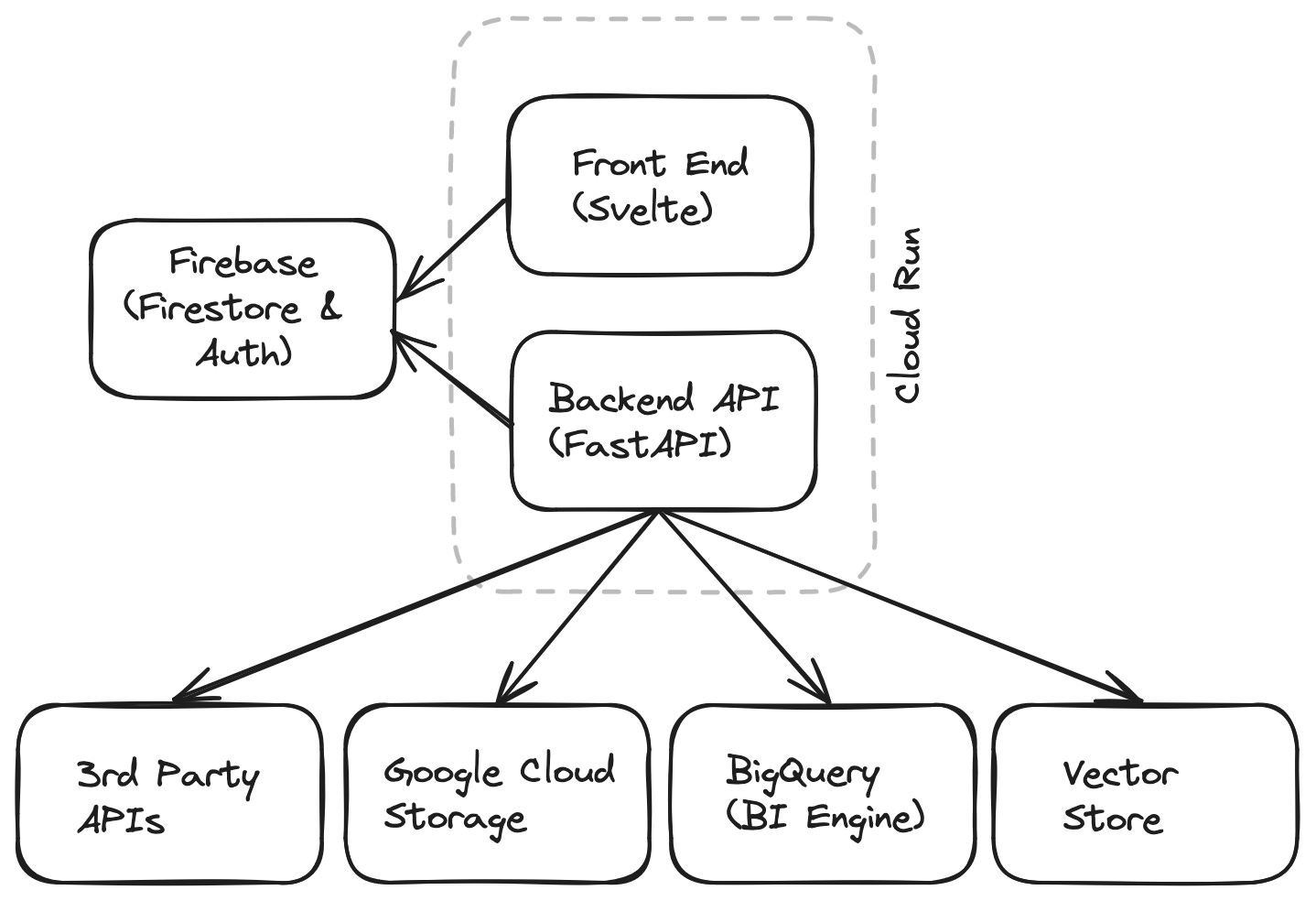
Front End
Our front end is created using Svelte and makes the assistant available in two ways. One is in a line of business application that each team member logs into to see their metrics for the accounts they are working on. The other is a pure chat interface application akin to ChatGPT and Gemini.
Having this ability to bring the assistant into a line of business application that is used daily has been phenomenal. It allows us to sprinkle some “magic” into the application. Users find it intuitive to click on the assistant button next to things like deals, accounts, graphs etc. to launch a conversation that is pre-populated with the context to make the conversation instantly useful.
Having this great UX for our users is arguably the most important part of the entire application. Without it the tool would just be another tool, instead it now feels like an enhancement to their workflow.
Backend
The backend API is the heart of our application. It is created using FastAPI and contains all of the logic we use to make the assistant work for the user.
We currently expose a set of endpoints from this API. Some of the more interesting ones are:
Chat - Used to interact with the agent and have the chat loop execute.
Memory - Used to get, set and delete key value pairs in the memory that is then fed into the context. We have the concept of both chat and user memory. Chat memory only exists for the specific chat while user memory is available across all chats for a user.
History - Used to get a list of previous chats for a specific user or get the full message history for a specific chat
The tools available to the agent are also part of the backend API. This is currently a python package in the backend codebase but could in future be moved into a separate project of its own that is imported into the backend.
Persistent Storage
We use a combination of Firestore and Google Cloud Storage as our storage layer for the application. We decided on this combination because of the ever increasing input token size for models (Gemini Pro 1.5 Flash can take 1 million input tokens) and the Firestore 1MB size limit on documents. GCS is used for pieces of information that cloud go beyond the 1MB Firestore limit.
GCS might seem an odd choice but the read and write latency proved fast enough in our testing and it vastly simplified our stack.
Sources
Our sources of data range from 3rd party APIs and BigQuery to internal systems. Most of these sources are used by our tools that the agent has access to. Here is a brief overview of what we use:
BigQuery (with BI Engine enabled) - Used as the source for some specific sets of data that is only available and curated in BigQuery.
SerpAPI - Used for web searches.
Vector store - Used to allow searching over all of the organisation’s internal PDFs and documents that serves as its knowledge base.
Final thoughts
I hope this overview has given you some insight into an example of an AI application. It is important to note this is only one example built against specific use cases. Not all AI applications need to be a chat bot, in fact I see more applications for LLMs in workflows and inside regular applications than I do for the pure chat interface type.
While the tech is not perfect it is certainly useful. It is up to us to remove the hype and focus on applying it correctly. Once you cut through the noise you realise that it is just another tool in your toolbox, it does not replace the toolbox.