Architecture of a B2B marketing insights platform

In my previous post, I introduced the SquareOne solution. This time round, I want to look at the high-level architecture that underpins it.
Below is a diagram showing the main components. One of the main goals was to keep the solution as cloud agnostic as possible. It is currently implemented on the Google Cloud Platform, but the GCP components can easily be changed for others on another platform.
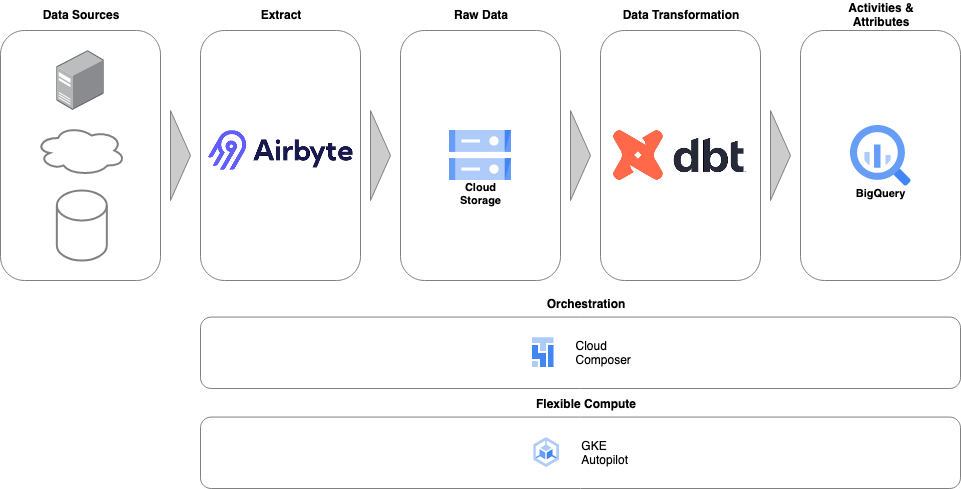
The architecture is deceptively simple yet extremely powerful. It has a low cost of ownership and does not need a large engineering staff to operate and maintain.
Let's look at some of the chosen components.
Data Extraction
One of the most time-consuming parts of any data solution is extracting data from the various source systems that feed it. Marketing and Sales teams use many software products, most of which are SaaS solutions.
Instead of writing custom code to pull data from APIs, I chose to use Airbyte instead. More specifically, the open-source version of Airbyte. This version allows you to spin up Airbyte in your cloud environment, keeping all your data under your control. It is an essential consideration for many organisations with a strict security vetting process for new software, especially SaaS tools. There is also Airbyte Cloud if you prefer not to manage your own instance.
Airbyte provides many connectors to SaaS products and other data sources such as databases, Kafka, cloud storage etc. There is also an active open source community contributing to the connectors, with improvements and new connectors coming through almost daily. You can find the current list of supported connectors here.
Building your own connectors is also a straightforward process. You can use any language you want since connectors run as containers on either Docker or Kubernetes. I have created a few custom connectors so far and will be looking to contribute these back to the Airbyte community.
All data from source systems is landed in its raw format in cloud storage which provides a cost-effective historical store of data and does not tie the data into any particular tool for processing.
Data Transformation
The data stored in cloud storage is modelled and transformed into activities and attributes using DBT and Google BigQuery. BigQuery allows for serverless SQL against cloud storage, while DBT provides the data transformation, testing, and documentation framework.
I use a custom DBT macro that allows you to write SQL scripts or Data Definition Language queries instead of the regular SELECT statements DBT recommends. It is used only where necessary, such as where I need to define external tables against cloud storage or where complex SQL is required to generate an attribute.
I cannot overstate the value of DBT as it is an absolute game-changer for analytics engineering.
The solution uses the open-source version of DBT, which we run on our GKE cluster. As with Airbyte, a DBT Cloud option is available if you prefer not to manage it yourself.
BigQuery provides the processing power to turn large amounts of raw data into activities and attributes. The attribute calculations are typically complex analytics queries over large volumes of data. It is difficult to beat the flexibility and value of processing large amounts of structured and semi-structured data with BigQuery, especially for this use case.
Data products built from the activities and attributes can be kept in BigQuery or could be created and stored in a different tool depending on requirements.
Orchestration
For orchestration, I use Google Cloud Composer (Apache Airflow). Airflow provides a lot of operators out of the box that connects to all the components in the solution. With Cloud Composer being a Google-hosted version of Apache Airflow, you avoid having the overhead of managing your Airflow cluster.
It is important to note that Airflow is used purely as an orchestrator. No custom python tasks or applications run on Airflow itself. Custom applications or python scripts are packaged and launched on our GKE cluster.
Ensuring Airflow only performs orchestration makes testing custom scripts and applications easier. It also allows you to move to a different orchestration tool if required with minimal effort.
Flexible Compute
A Google Kubernetes Engine (GKE) Autopilot cluster is used for all custom applications and tasks. GKE Autopilot charges for the duration your containers run and scales up and down to meet demand automatically.
The flexibility and scale it provides and the cost savings of not being charged for idle resources help make the solution cost-effective. There is no "ops" or managing of the cluster; simply vast scalable compute resource you can tap into when needed.
Other Components
There are, of course, other components on the periphery not included in the diagram. These would be for managing Infrastructure as Code (IaC) and CI/CD.
For our Infrastructure as Code, we use the open-source version of Terraform for the same reasons mentioned earlier on other components.
For our CI/CD, we currently make use of Github Actions. The steps can be performed via any other CI/CD pipeline tool, so there is nothing that ties the solution to Github.
Final Thoughts
The architecture of the solution is straightforward by design. It did not start out like this. There was a period when additional components were used, such as Kafka, custom integration code, and apps running on Kubernetes.
Those components only added complexity and maintenance overhead while delivering no real additional business value for the problem being solved.
The guiding principle of "delivering maximum business value from development effort while keeping ownership cost as low as possible" helped guide the solution's architecture to what it is currently.