LLMs and function/tool calling
What is it and how to achieve it with any LLM, not just those that support it in their API/SDK

Function calling with LLMs cause a lot of confusion. The overhyped marketing combined with the YouTube tech-bros is not helping the situation.
What I am going to explore in this post is what it is, how it works, and how to achieve this with any LLM regardless of if its API or SDK supports it.
What is function/tool calling with LLMs
LLMs are next token predictors. That’s it. Nothing more, and nothing less. Based on the input (prompt) it will predict the next most likely token, then re-evaluate the original input + predicted token to predict the next token.
This loop runs until the LLM reaches its end where there are no more tokens to predict, or it has reached the number of output tokens it is allowed to produce.
Again, that’s it, nothing more and nothing less. LLMs DO NOT call functions. Regardless of what you have been told, they simply don’t. If your LLM API/SDK or model of choice calls functions for you then there is a layer of software wrapped around it that is taking care of this and invoking the function(s).
When you dig into the documentation for Google’s Vertex AI and that of OpenAI this becomes clear. What is described in both is that the calling client (your software, ChatGPT, or whatever service you are playing with) sends to the LLM a list of the functions that are available, a description of each of them and a description of the parameters each function takes. The LLM will then return a response that states which function to call and which arguments to pass to the parameters of the function based on the prompt it received.
Once you receive this response from the LLM the calling client is responsible for executing the function and then returning the result back to the LLM as part of an updated prompt, now containing the output from the function. The LLM then returns a response by either specifying another function to call or returning a response that can be sent to the user by the calling client.
Here is the diagram from Google Cloud Vertex AI showing this flow:

And here is an extract of the OpenAI API documentation describing exactly the same steps.
The basic sequence of steps for function calling is as follows:
1. Call the model with the user query and a set of functions defined in the functions parameter.
2. The model can choose to call one or more functions; if so, the content will be a stringified JSON object adhering to your custom schema (note: the model may hallucinate parameters).
3. Parse the string into JSON in your code, and call your function with the provided arguments if they exist.
4. Call the model again by appending the function response as a new message, and let the model summarize the results back to the user.
So now you know that there is no magic! This is good old fashioned software development with some LLM magic sprinkled in.
NB! Remember that LLMs will hallucinate, and this also applies to the arguments it specifies for the parameters of the function call. Code accordingly!
How to use any LLM to call functions/tools
So now that we know how it works, what is stopping us from using any other LLM that does not have a function or tool calling capability to perform the same action? The answer is nothing.
Almost all the SDKs and LLM APIs supporting this require you to send the definition of your functions/tools as a JSON Schema object or an OpenAPI Schema. So given that most of the LLMs are trained on loads of JSON we can take advantage of this by passing our list of tools to the LLM as a JSON object and specify a JSON Schema object that we would like to get back.
So, our plan is:
Create a python dictionary that contains the name of the function and a description of it and its parameters.
Pass this to the LLM with a prompt instructing it to call functions when it requires to.
Receive the response and process it, calling any functions it specifies with the arguments it specifies for each parameter.
Return the result of a function call to the LLM as an updated prompt.
If not function call is received from the LLM but instead a message to pass to the user then we send this output to the user.
Profit! (ok not really, but you get the idea :D )
I will be using text-bison on Google Cloud Vertex AI to try the above out. This is a TextGeneration model type that does not have function calling as a capability. I will also be using my Modelsmith python package to helps get a structured response from the LLM.
Lets look at an example. (The code for each screenshot can be found here on GitHub)
The functions
We set up two functions for our LLM. These are very simple functions to help keep the example as short as possible. We include a print statement to show when the function is executed and what arguments were passed to it.

Next up is doing some prep work to provide the LLM with a list of function it can call and creating a dictionary with the function name mapped to the function object. This dictionary is there to help us avoid a bunch of if statements, so is purely for convenience.

I am using inspect.getdoc to get the docstring of the functions and add it to the description. For the parameters I use the Pydantic TypeAdapter class to get the JSON schema of the function’s parameters. This saves us having to build that out ourselves.
The response object
Now that we have our function related work out of the way it is time to turn our attention to the Pydantic model we want to get back from the LLM as a response. In this example it is a combination of either a message (if the LLM has enough information to answer the question) or a function (that needs to be called) and arguments (for us to use when calling the function).

The descriptions on the Pydantic model’s properties are important as this is fed into the LLM’s prompt and helps give additional information of what is expected from the LLM.
The prompt
Moving on we look at the prompt that we will use.
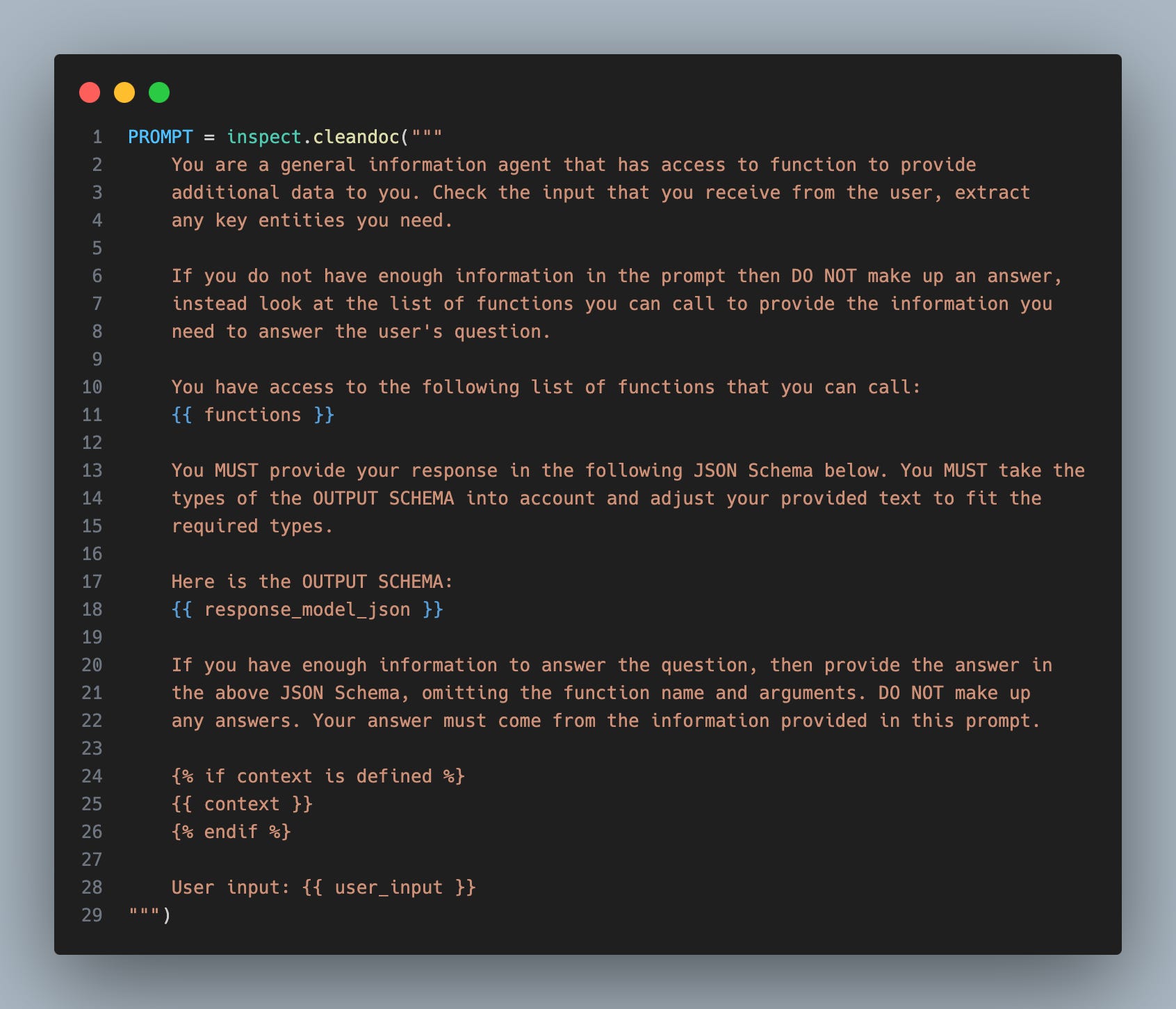
The prompt makes use of jinja templating to add the functions, response model, and finally the context to the prompt.
There is so much that can be said about prompts and “prompt engineering”, but I will leave that for another post. Suffice to say that it is less engineering and more magical trial and error.
The application logic
So, all that is left for us to do is put in some application logic to have the user ask a question and see if we get our functions executed and the question answered based on the data they return.

Let’s break the application logic down according to the main parts.
Lines 1 - 5
Using Modelsmith, we create our instance of Forge specifying the text-bison model and pass it the LlmResponse as our response model, and also passing in our custom prompt.
Lines 7 - 10
We create our prompt_values dictionary and pass in the functions available as JSON. The context is initialised to None as we will only use it to capture the output of a function call when that is required.
Line 11
The user is asked for input which we will use as the input to the prompt sent to the LLM.
Lines 14 to 44
This is the main body of our application loop.
First, we initialise our counter as we are only allowing two iterations of the logic. This is done to ensure that we do not end up in an infinite loop. Remember, the user’s input is sent as part of the prompt and as we have not built any safeguards into this example the wrong user input can cause the application to loop indefinitely. (Hello prompt injection!)
We check to see if we have received context, and we add it to the prompt_values if we did.
Next up we generate our response from the LLM, passing in all the arguments needed.
Based on the response from the LLM we go and retrieve the function to call, if one was specified. You can see the use of our FUNCTION_MAP constant in getting the function to call instead of using if statements. Once a function has been called the response from it is assigned to the context variable which will be added to the prompt_values in the next iteration of the loop and thus make it into the prompt going to the LLM.
If we have a message back from the LLM instead of a function call, then we print that out to the user and we break out of the loop.
Otherwise, we go around once again until we break out of the loop without returning a message from the LLM to the user. If this happens, we print a simple message to ask them to rephrase their question.
The results
Let’s take our toy example for a spin. First up we will ask it for the weather in Amsterdam.

Next up let’s ask for local news in Manchester.

And there you have it. Function calling with a model that does not support it.
Wrap-up and caveats
We looked at function calling and realised it is simply an LLM telling us what function to call with which arguments for the function’s parameters. Hopefully demystifying function/tool calling in the process.
We then built a very basic example script to test out function calling with a model that does not have this capability in its SDK or API.
This was a very basic example to illustrate the concept. While it works it does not mean that it will always work reliably. This is the catch. When it comes to LLMs you are looking for reliability and predictability above all else. You need deterministic behaviour. Models that have function/tool calling as part of their SDK and API are typically trained to perform function calling, while other models are not. Hence, they will give better and more consistent results.
The usual caveats apply here, code defensively when it comes to LLMs. You are placing a non-deterministic element that makes up results inside your application logic and should make sure that it cannot cause problems.
I hope this has been a helpful example to show the concept. As always leave a comment or reach out to me if you would like to discuss this further.
If you missed it earlier, the code for the example script can be found here on GitHub.